Format Preserving Tokenization – Tokens that match the format and length of original data
Format Targeting Tokenization – Specify token character type and length regardless of original data
Random Number Generation (RNG) – In software or an external hardware security module(s) (HSM)
Encryption Generation – Leveraging an encryption technique using a specific encryption key
Single Use Tokens – Unique token generated every time any clear data is input for single use
Multi-Use Tokens – Unique token generated once for a piece of data and reusable
Token Formats – Alphanumeric or numeric (format preserving or targeting) or binary data format
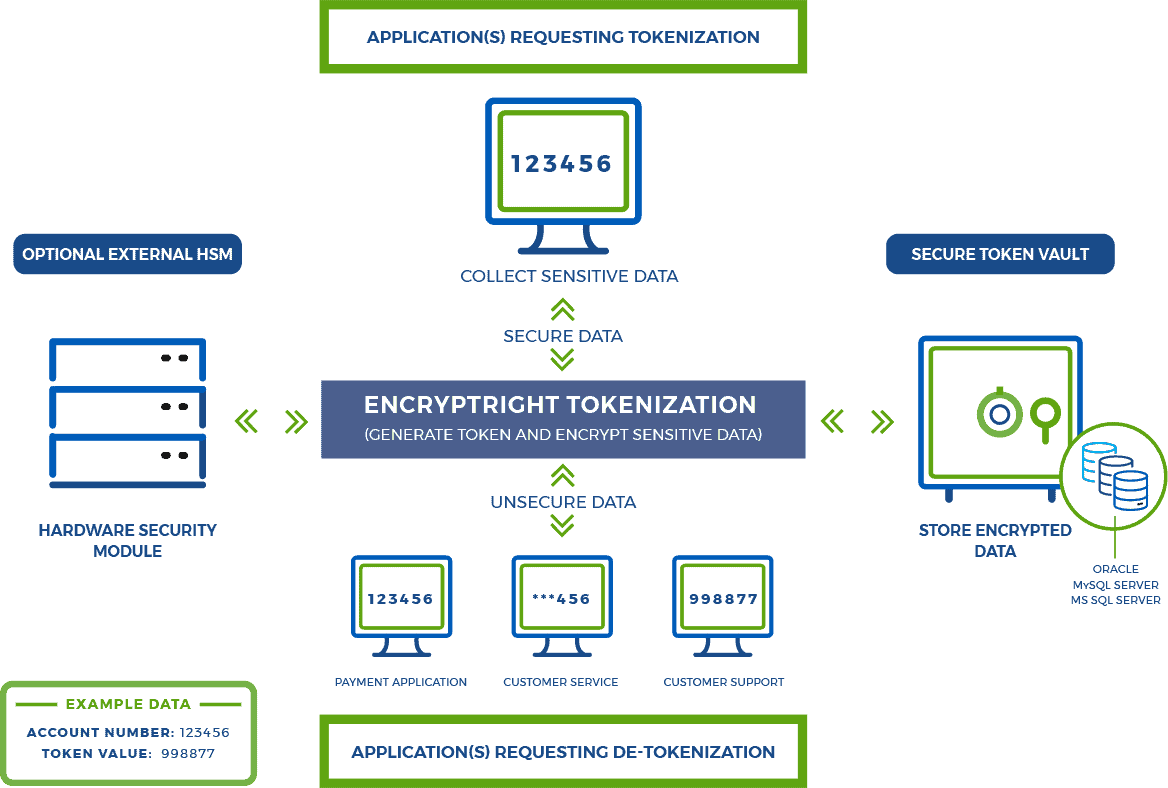
Tokenization, in the context of electronic data protection, is the process of substituting a surrogate value (or “token”) for a sensitive data value in a processing system. These surrogate values could be Reversible Tokens, which are able to be returned to their original data value, or Irreversible Tokens, which remain irreversible and cannot be reidentified. When using Reversible Tokens, effective commercial implementations must allow for the high-speed cross-reference of the surrogate token to the original data, when the original value is required. However, such cross-reference should be limited to authorized users who can access the original sensitive data and must be otherwise impervious to penetration by cyber thieves and other unauthorized users.
EncryptRIGHT® Tokenization software helps enterprises reduce potential audit scopes, comply with regulations, reduce contingent liability associated with potential data breaches, and increase tangible effects of data protection altogether, while providing value in many industry use-cases. Banks seeking to comply with consumer banking privacy regulations, governmental agencies managing Social Security numbers, and any enterprise seeking to diligently, cost-effectively secure sensitive data to comply with industry standards — all can apply tokenization to achieve their goals.
Vaulted Tokenization – EncryptRIGHT Tokenization software generates tokens for use across the enterprise, then encrypts and stores all original sensitive data in a secure database (or Token Vault) along with the corresponding tokens that represent the data, such that each token can be cross-referenced or mapped to its originating data, often referred to as a look-up table. Token vaults offer the most flexibility in terms of token types and generation techniques.
Vaultless Tokenization derives a token from a mathematical algorithm, often using format preserving encryption (FPE) techniques. When a token’s original data is required, the token-generating algorithm and cryptographic keys can be used to restore the original data (a process commonly referred to as de-tokenizing), without needing to reference a centralized token vault.
EncryptRIGHT supports both random tokens (e.g., using an HSM) and encryption-generated tokens (e.g., using format preserving encryption).
Tokenization solutions that leverage token vaults can take advantage of more token-generation techniques than vaultless, such as the use of random-number-generators, and all original data is encrypted and centrally stored (defended) in a single secure location. Because of this Vaulted Tokenization solutions are often considered more flexible and more secure. Because de-tokenization can be distributed in a vaultless environment, Vaultless tokenization is considered by many to be faster, with less total lag. While there is much debate over the right solution, vaultless environments have proven sufficiently secure in many cases and modern token vaults in very large deployments have proven to be very fast and reliable.
